Cross Correlation
Background
Climate change is one of the top issues of today. Not only is it a global issue, but it affects all species due to mostly human activity. Tracking the biodiversity of species, specifically birds in this case, can help us gauge how much climate change has damaged these populations and the undergoing changes in their habitats and ecosystem. Our focus is on birds and we’re hoping to use bird audio to measure the biodiversity of birds within our area and potentially identify endangered birds. We want to be able to passively identify and differentiate these birds in a reliable way.
The issue with trying to approach this problem via machine learning models or neural networks is that these models need labeled and identified audio recordings which require manual input and time. Manual audio data labeling, while having the potential to be more accurate than automated methods, is a very time-consuming process and can be prone to inconsistencies due to human input error. These problems can all negatively impact the model and leads us to believe that it is worth looking into an alternative to manual audio labeling in order to generate sufficient audio data for acoustic biodiversity models.
Data
The datasets that were used have been collected by the San Diego Zoo, which contain .wav files of bird audio from different sources. The primary data we use for this pipeline come from the Scripps Coastal Audio Reserve and Peru and is unlabeled data. The remaining data is sources from the UCSD Engineers for Exploration team and represent labeled bird audio that is titled with the name of the species of interest.
Each dataset the San Diego Zoo Conservation Technology Lab (CTL) shares with UCSD Engineers for Exploration will remain the property of San Diego Zoo Wildlife Alliance (SDZWA) and cannot be shared or disseminated any further without first following up with the CTL.
Overview
The goal with our pipeline was to create a product that could reliably and quickly create labeled audio data that could be used for training machine learning models. Our solution was the cross-correlation pipeline, which we use to label data automatically. At a basic level, the cross-correlation pipeline takes in a template audio file for a given bird’s call and runs it across a longer audio file, identifying where this template sound or similar occurred. These similarities can allow us to identify the presence of a species in an unlabeled audio clip and label it for use in machine learning.
If we can improve the workflow and speed up the process of gathering training data without sacrificing accuracy, we will be able to learn more about the biodiversity of different species. Monitoring wildlife gives us a better understanding of rare, threatened, or endangered species to help us reallocate funds and provide assistance and protection to those species that need it.
Methodology / Model
The first step in performing cross-correlation is deciding on data to run the pipeline on. In our case, to make sure cross-correlation was working as intended initially, we chose to run the pipeline on ScreamingPiha audio data. Because the screaming piha is one of the loudest birds, it would be the easiest to identify and test on.
First we extract a template from an audio clip by listening to the clip itself and looking at the spectrogram. We then isolate a section of the audio containing a peak, and that will be our template for the chosen species clip.
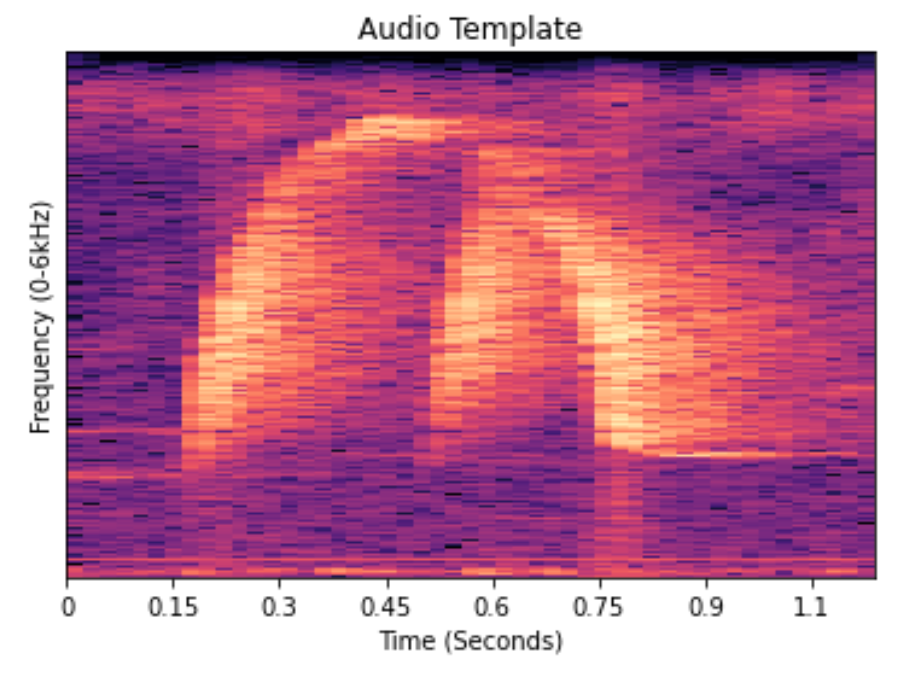
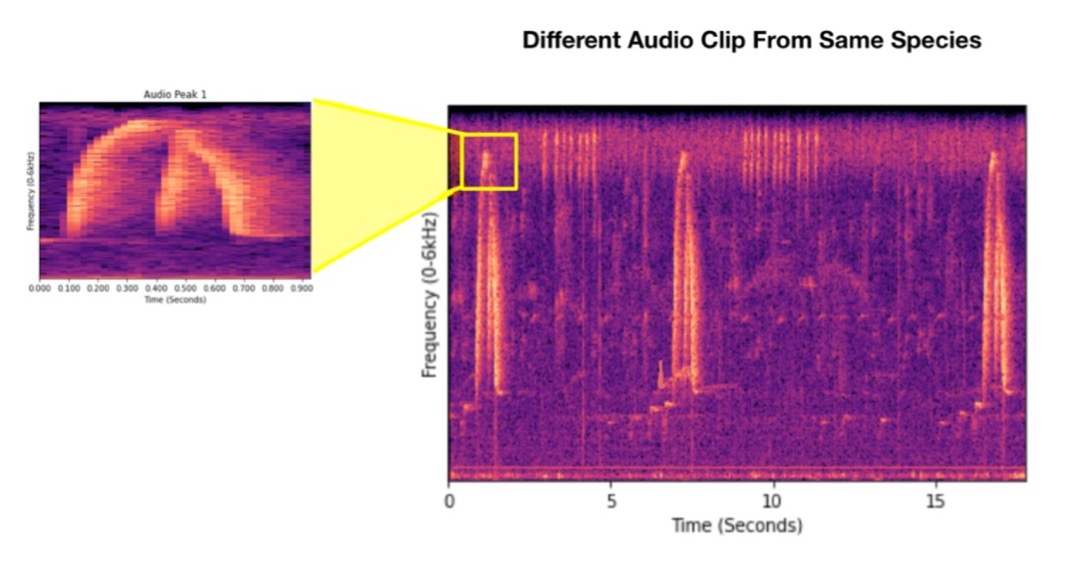
Next using a full length clip (of the same species for demonstration purposes), we perform simple exploratory data analysis by outputting spectograms to visualize the audio. If we zoom into the peaks of this clip, we can see that it is very similar to the template!
Then, using SciPy’s correlate2d function which performs cross-correlation, we are able to view a spectogram of peaks alongside a local score array that represented our cross correlation model’s prediction on the audio. The model automatically annotates each call and in the figure below, we can see the comparison between the human annotations vs the automated annotations.
Cross Correlation: Human vs. Automated Annotations
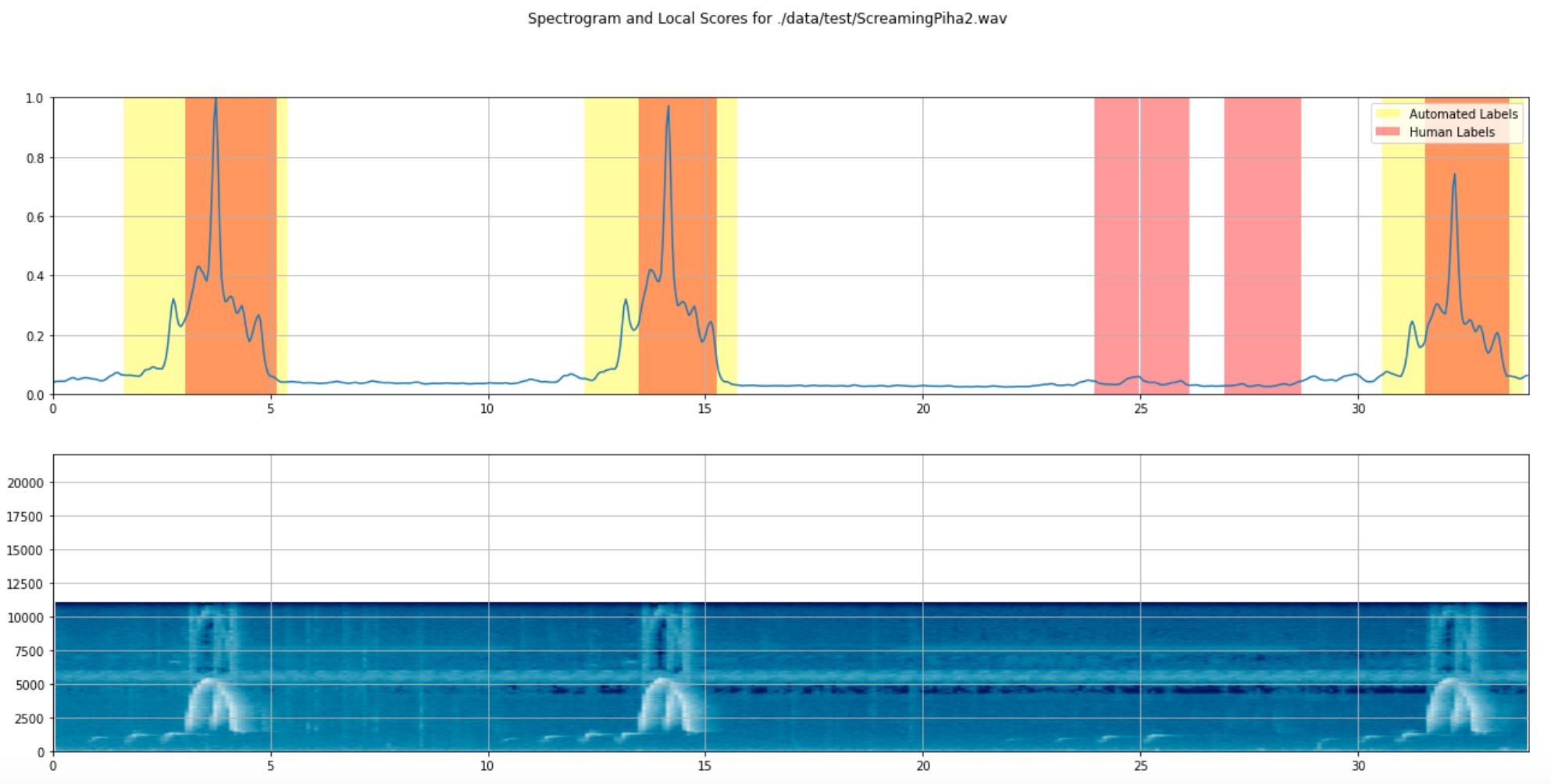
Here we can see that overall, cross-correlation does a good job of annotating the main parts of the call. Although the automated couldn’t detect the preliminary calls as a human annotator would, our labeled data for the machine learning models wouldn’t require it.
Analysis
To test out our pipeline, we took an audio template of the Screaming Piha and ran cross-correlation across 10 different audio files. In general, the cross-correlation algorithm, albeit slow, was quite effective at detecting peaks. In some cases where the spectrogram of the audio file was noisy, it could be difficult to detect some peaks and may have incorrectly deemed a section of the audio as a peak where there is none. However, in all of the files, it captured at least 50% of the peaks and in 7 of the 10 audio files we ran the template across, it captured all of the peaks successfully.
Results / Conclusion
Overall, we were happy with the performance of the model at the current stage but feel that it could be improved further. It was moderately accurate at detecting peaks of the data but we want to minimize false positives and negatives to approach classification levels closer to that of human annotation. Additionally, running cross-correlation on 10 distinct audio clips took about 40 minutes which when done by a human, would typically take closer to 10 minutes to perform. Cross-correlation does have the advantage of not requiring active input to label data but paired with its imperfect accuracy, we felt that it would currently be preferable to continue performing human annotations to get labeled data. Moving forward, we want to improve the speed of the cross-correlation algorithm to run it more effectively on larger sets of data. In addition, we want to manually evaluate its effectiveness on different sets of data beyond the Screaming Piha, potentially with different isolation parameters. In addition, we intend to make the pipeline both more fluid and simpler to use so that any template can be passed in alongside full audio data and generate local score arrays with little manual input.